Documentation
TestData
Description on the Test Data
If you are looking at this page, you are probably curious about the test data, or you are trying to figure out the discrepancy between your local score (produced by the validation data) and the score we have on the leader board.
In short, as you may have realised, the test data is not a simple train-test split. In fact, we made it deliberately different from the training distribution.
The test data on our server contains unseen cases of different atmospheric chemistries and temperatures. This is to make sure that your solution generalises appropriately.
While we can’t tell you exactly what we have done, we are happy to provide some clues. The test set is composed of a mixture of different atmospheric assumptions. On top of the atmospheric assumption that we used for generating the training set, we have added several different atmospheric assumptions, each of them concerns with different aspects of atmospheric dynamics. Depending on the physical phenomenon being explored, they have varying degrees of similarity to the training atmospheric assumption (some are rather different!). The core idea is to test the robustness and reliability of the model under varying degree of data drift.
Scientific Reason
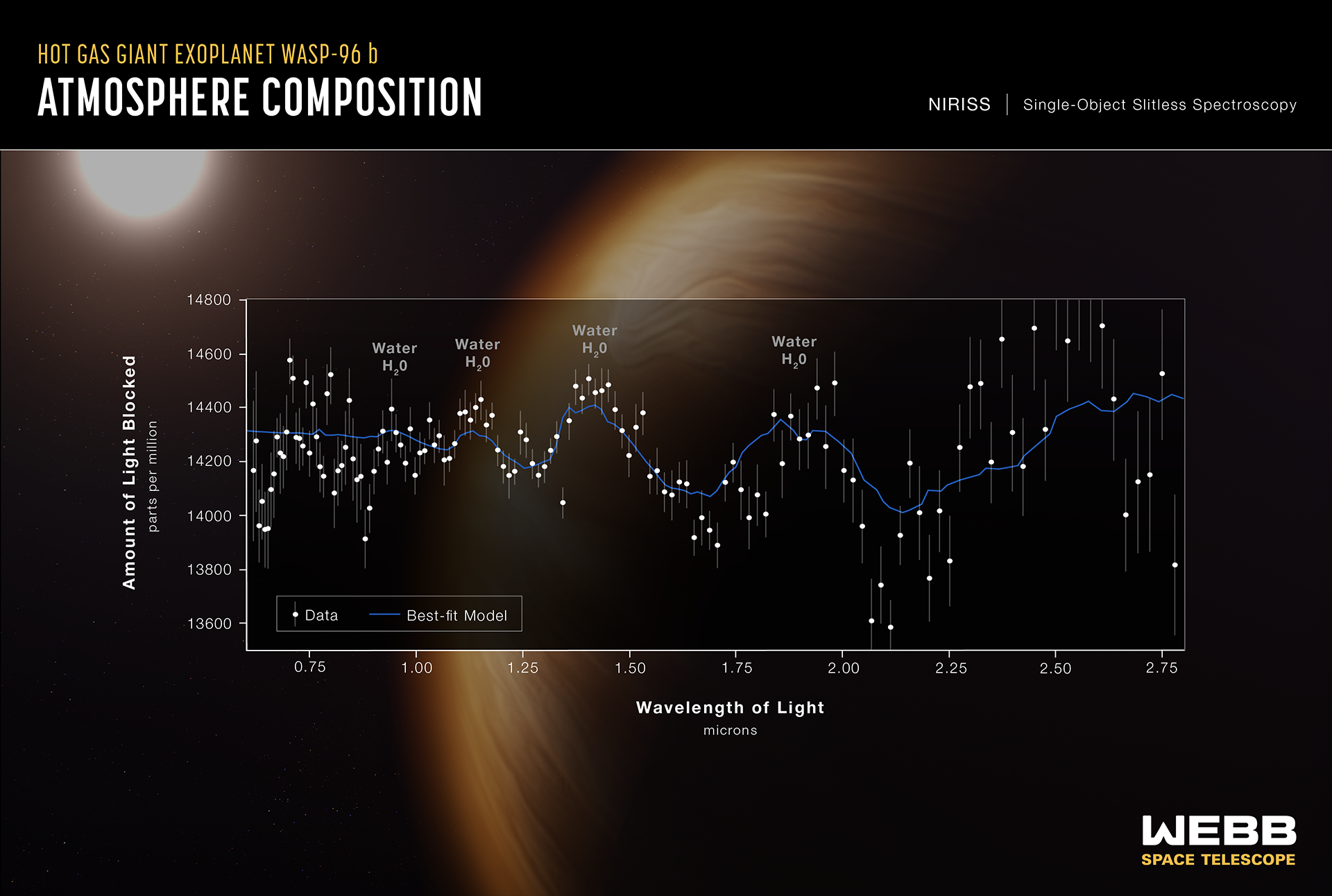
We don’t just create a different test set to make your life harder. Exoplanet characterisation is a field where the ground truth is difficult to come by (we can’t physically travel to the planet and take measurements). The models we built are always a simplification or quite often, wrong description of what is actually happening with the exoplanet’s atmosphere. The recent release of WASP-96 b observation from JWST NIRISS is an excellent example (see below). While our best fit model is able to figure out the existence of water from the data, it is obvious that our model cannot fully explain the fluctuations in fluxes (see 0.75 - 1 micron for example).
We would like to simulate the same scenario in this competition, i.e. we want to expose the submitted solutions to distributions that are different from their training distribution. Our end goal is to look for a ML solution that can maintain consistent performance when exposed to data that is drastically different from its training distribution. To evaluate the performance, all the test data we produced are complemented with corresponding retrieval results. The retrievals, or sampling procedure, are carried out using the same atmospheric model that produced the training data in the first place.
But surely, if you apply the training atmospheric model to the test data that is different, the answer will be wrong or biased?
Yes, you are right. The atmospheric model may struggle to match the observed data, as it may lack necessary physics or fail to account for other astrophysical or instrumental effects. A key philosophy behind atmospheric retrieval is to compare different models in a relatively objective way, to determine which one best fits the observed data. While many models are likely to be inaccurate to some extent, what matters is whether they can accurately reproduce the posterior distributions, even for spectra they have not seen before. Having a model that can do this allows us to approximate the Bayesian Evidence, which is a commonly used metric for comparing the fit of different models.
Of course, there are other tools for model comparison such as BIC and AIC etc, they both depend on the likelihood value, which relies on a good estimate of the posterior distributions.
Why dont you just just use sampling-based retrieval like you did when producing the ground truth?
Yes and no. It’s true that we can always use this method - in fact, it’s a method we’ve been using for the past decade. However, with the arrival of JWST and soon after, Ariel, we need another solution. Simply put, sampling-based solutions will become prohibitively slow.
Can you produce a training set retrieved with multiple atmospheric assumptions?
We can but there are two obvious issues here. 1. Retrievals are expensive to obtain. We spent 5M CPUh to produce the training and test set, this is a lot of computational resources and we would prefer not to repeat the same exercise for other atmospheric models. 2. Which models should we pick? We simply don’t know as unfortunately, we don’t have prior knowledge on what to expect for exoplanetary atmospheres (it is still ongoing research).
We are certain that there are other ways to circumvent these limitations, unfortunately, with our limited brain power, we did not manage to make it happen. We welcome your suggestions. Please feel free to ask them in the slack channel and/or email us directly.
Can you describe what kind of atmospheric assumptions has been used to produce the test set?
Very sorry but we cannot tell you :(